Total_relight Paper Reading
foreground estimation, relighting, compositing.
each stage can be tackled without the use of priors.???
需要:一张RGB图片和一个HDR环境光贴图
具体做法:
- 用深度卷积网络和改进了的Disentangled Image Matting实现抠图。
- 13 encoder-decoder U-net
Matting Module
深度卷积网络
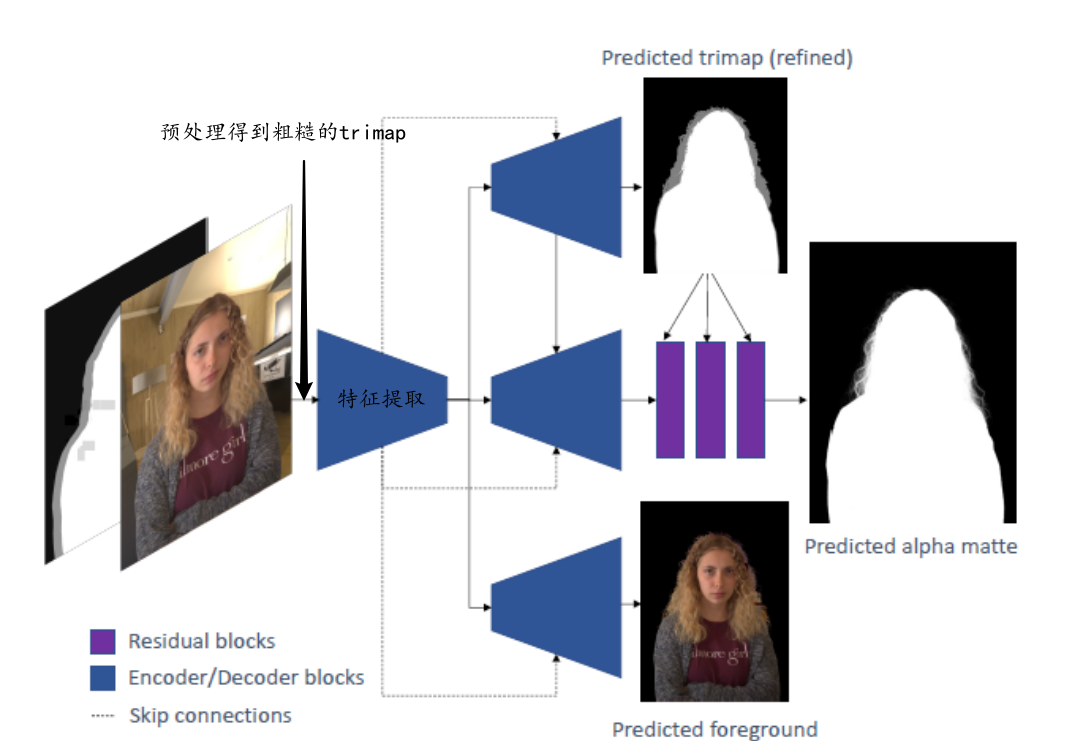
图片和粗糙的trimap(off-the-shelf foreground segmentation network得到)经过U-Net得到精致的trimap、$\alpha$、F
图像特征提取用3*3的卷积核、ReLU激活函数,32,64,128,256,512
Trimap Refinement用4层,256,128,64,32, Leaky ReLU
Alpha Matte Prediction的结构和T日麻批 Refinement一致,但它的输出经过77,55,3*3的卷积
Foreground Prediction结构和Trimap Refinement一致
Loss Function详见A.6,部分对应不太上
Relighting Module
输入应resize为1024*768的扣除的人像图,输出为每个像素点对应的法向量、反照率

Geometry Net
因为法向量更容易学习,所以先训练法向量。U-Net with 13 encoder-decoder layers and skip connections.每层都是3*3卷积 with Leaky ReLU, 32, 64, 128, 256, 512, 512 for encoder, 512 for bottleneck, 512, 512, 256, 128, 64, 32 for decoder. The encoder uses blur-pooling [Zhang 2019] layers for down-sampling, whereas the decoder uses bilinear resizing followed by a 3 × 3 convolution for upsampling.
Albedo Net
训练好geometry net后,将得到的前景和法向量连接起来作为1024*768*6的输入,通过和Geometry一样结构的U-Net得到albedo。
Light Map
不是网络,交给charles
Shading Net
由Specular Net和 A final Neural Renderer 组成
- Specular Net以Albedo、Foreground、Specular light map作为输入,A lighter weight U-Net with 13 layers with 8, 16, 32, 64, 128, 256 filters for theencoder, 256 filters for the bottleneck, and 256, 128, 64, 32, 16, 8 filters for the decoder runs 3𝑥3 convolutions with Leaky ReLU activations. 输出为四维,应该是法向量加权重,记为W。最后得到的single specular light map为$\hat S(u,v)=\sum_nW_n(u,v)S_n(u,v)$
- A final Neural Renderer以albedo、diffuse light map、上面得到的$\hat S$为输入,返回最终relit的人像。和Geometry Net一样结构的U-Net
Compositing
用𝐶 = 𝛼 ∗ 𝐹 + (1 − 𝛼) ∗ 𝐵组合。作者也尝试过用网络,效果不佳。
训练细节
ADAM optimizer
学习率$10^{-5}$
每次迭代8张,1M次迭代,长达7天(8个NVIDIA Tesla V100 GPUs, 16GB memory)
matting和relighting分开训
Loss Function详见4
数据产生
暂时没看